
Informação, biologia e evolução
A teoria da informação de Shannon e a Biologia:
Informação, este talvez seja um dos termos mais usados nas últimas décadas e uma constante em nossas vidas agitadas com demandas profissionais e acadêmicas crescentes, quase soterradas pelo mar de conteúdo que é a internet. Informação também é um dos termos mais mal compreendidos e distorcidos apesar de seu apelo intuitivo óbvio. Em artigos anteriores, abordei um dos argumentos mais conhecidos dos criacionistas, o de que não existem evidências para, ou mecanismos naturais que possibilitem, o aumento da "informação genética" (ou biológica) nos seres vivos ao longo da evolução (veja a parte 1 e parte 2). Este é um dos argumentos mais infelizes já propostos, principalmente, por que confunde diversas questões diferentes e usa dois pesos e duas medidas. O primeiro problema é que seus proponentes utilização o termo "informação" de forma metafórica (sem reconhecer este fato), mas tratam-no como se fosse algo definido rigorosamente, às vezes mesmo, invocando sua utilização nas ciências exatas, especialmente no estudo de sistemas de comunicação e de transmissão de dados e na computação.
Aquilo que poderíamos chamar de "informação genética", em um sentido menos técnico, pode ser facilmente aumentada por uma série de tipos de mutações, baseados em processos e mecanismos mutacionais bem conhecidos, associados a modificação funcional posterior destas seqüencias por mutações adicionais. Dentre os vários mecanismos estudados, a duplicação gênica (através do "deslise da DNA polimerase" e/ou crossing over desigual) se destaca, uma vez que, a partir da duplicação de um gene, uma das cópias estará livre para se modificar, sem prejuízo da função original; ou ambas as cópias podem se modificar de forma compensatória e mutuamente dependente.
A divergência entre as seqüencias duplicadas e a adoção posterior de papéis diferentes ou complementares pelas mesmas são, inegavelmente, fontes de aumento de informação. Mais especificamente, vários modelos para o aumento, complexificação e "embelezamento" genômico (para usar o termo de Michael Lynch) têm sido propostos utilizando-se de modelos matemáticos muito robustos, simulações computacionais extensas, enorme compilação de dados genômicos comparativos. Tudo isso usando a boa e velha genética de populações e informações demográficas das populações de animais modelos e de espécies selvagens. Michael Lynch oferece uma magnífica demonstração de uma destas abordagem que basicamente funciona como um modelo neutro para a evolução genômica (Lynch, 2007). [Veja o post Além da seleção natural ... sobre o trabalho de Lynch e assuntos relacionados.] Este modelo foi recentemente comentado e tratado a partir de uma perspectiva um pouco mais ampla por Eugene Koonin (Veja Kooning, 2009 e veja figura ao lado). Processos estocásticos, como a deriva genética, associados a uma menor eficiência da

seleção natural, por causa da diminuição dos tamanhos efetivos das populações - durante a evolução de procariontes para eucariontes, mas principalmente de eucariontes unicelulares para eucariontes multicelulares - criam condições apropriadas para o aumento do tamanho genômico, complexificação da estrutura dos genes (aquisição de regiões UTR, promotores e de introns e exons) e dos circuitos genéticos, como um todo. Modelos baseados em seleção natural, portanto, que enfatizam a importância de fatores adaptativos também têm sido propostos e ativamente investigados.
De forma complementar, como abordado em outro conjunto de dois artigos (aqui e aqui), sobre a Evo-Devo, os mecanismos bioquímicos, biofísicos e celulares e teciduais da [auto]construção dos fenótipos têm sido esclarecidos, sendo ligados a organização em rede dos circuitos genético-desenvolvimentais e às forças físicas e processos químicos 'genéricos' envolvidos nas interações celulares e teciduais. Por tudo isso, temos uma compreensão cada vez melhor de como a "informação" aumentou nos seres vivos, especialmente em seus genomas, por isso as reclamações dos criacionistas e antievolucionistas de plantão simplesmente não procedem.
Estas considerações, entretanto, lidam apenas com a versão semanticamente orientada (veja mais sobre isso na seção "O que é informação?") do conceito de informação, aquela mais comumente adotada em biologia e menos rigorosa doponto de vista teórico e matemático. Entretanto, como o antigo deus do panteão Romano, Jano, a "informação" também é uma senhora de duas caras. Sem demerito algum para seus dois significados.
O segundo tipo de utilização do termo "infomação", porém, também é frequentemente distorcido e alardeado por criacionistas, principalmente os da estirpe do Design Inteligente. Aliás, um dos principais defensores desta abordagem pseudocientífica, o matemático e teólogo William Dembski, do Discovery Institute, foi chamado por seus asseclas alguns de "o Isaac Newton da teoria da informação", mostrando que é de exageros e hipérboles que

vive o movimento criacionista. Porém, mesmo caso nos voltemos para definições um pouco mais técnicas de informação - por exemplo, ao associarmos esta grandeza a nossa capacidade de representação ou armazenamento em bits (veja mais sobre isso adiante) - as objeções criacionistas não procedem, pelo simples fato de que muitas mutações, como as que envolvem a inserção de nucleotídeos no genoma (e mais ainda as duplicações gênicas e genômicas), aumentariam o número de bits necessários para codificá-los. Assim, a idéia de que mutações apenas poderiam diminuir ou deteriorar a informação genética é tola e sem sentido. Veja por exemplo o verbete da skepticwiki, Mutations_and_Information.
As versões mais formais e técnicas do conceito de informação são também vitimas dos usos e abusos dos criacionistas que até hoje não foram capazes de dar contribuições reais ao campo, muito menos foram capazes de produzir aplicações da teoria da informação relevantes na biologia. Muito pelo contrário, o obscurantismo típico deste movimento desvia a atenção dos trabalhos científicos sérios (teóricos e empíricos) utilizando-se da teoria da informação aplicada à sistemas biológicos e mesmo á evolução destes sistemas. Mesmo aqui, são os biólogos teóricos e computacionais, ao aliarem-se a matemáticos, físicos e cientistas da computação, seguindo uma abordagem evolucionistas, que têm dado grandes contribuições à área.
Neste ponto é fundamental que compreendamos que, mesmo neste sentido mais técnico, o aumento do conteúdo informacional em sistemas biológicos é um fato, embora aqui o contexto e a precisão das definições de "informação" e os limites de aplicabilidade deste conceito precisam ser encarados com cuidado e compreendidos se quisermos utilizá-los na investigação científica.

O que é informação?
A informação é originada de "diferenças" em alguma quantidade física que pode ser analisada em seu nível sintático dos dados físicos. (Fabris, 2009)
De acordo com Fabris (2009), os dados são objetos abstratos representados em um algum tipo de suporte físico, de acordo com alguma convenção que permita de forma inequívoca distinguir os símbolos, uns dos outros, de algum alfabeto em particular. No entanto, podemos analisar a informação também em seu nível semântico de significado. Podemos dizer também que, embora a informação sintática encontre-se no nível físico dos dados brutos, seu corolário semântico refere-se a objetos além da mensagem, como suas relações lógicas, seu contexto, que é, aquilo, que chamamos de "significado" (Fabris, 2009).
Normalmente, quando nos referimos a "informação", em nosso dia a dia, pensamos, na verdade, naquilo que poderíamos chamar de “informação semântica”, deixando de lado o nível puramente sintático do qual as terias matemáticas e computacionais lidam. Essa dupla face da informação, que parecem habitar dois planos diferentes que simplesmente não se intersectam, talvez seja a principal causa de confusão quando falamos de informação "biológica". Nesta situação, não é completamente claro se estamos considerando apenas os dados crus (como coloca Fabris, 2009), ou se estamos atribuindo um significado biológico semântico mais específico a esses dados (Fabris, 2009). Esta confusão terminológica cai facilmente nas mãos dos criacionistas tradicionais e, mas recentemente, aos criacionistas do Design Inteligente. Porém frisar as diferenças é essencial para que tenhamos uma compreensão clara do que estamos discutindo:
"Como tal, torna-se óbvio que a informação semântica necessária necessita da aquisição de dados sintáticos e o significado só pode ser compreendido por um sistema que é capaz de acumular informação sintática, juntamente com todas as relações associadas a estas partes da informação, constituindo o que chamamos de conhecimento; a estratificação do conhecimento pode ser chamada experiência, e entender um significado subentende a capacidade de trazer de volta dados de uma experiência anterior vivida no passado. Como conseqüência, podemos dizer que “sintaxe”está "dentro" de dados, enquanto a “semântica” está "dentro" do contexto. Além disso, enquanto a informação sintática é objetiva (depende dos dados brutos), a informação semântica é (inter)subjetiva, pois depende da experiência compartilhada pelos sistemas que geram informações" (Fabris, 2009).
A partir daí, é compreensível como, no início da revolução molecular - logo que o primeiro seqüenciamento de DNA foi realizado - fosse natural indagar qual seria o "conteúdo da informação" do DNA, uma conseqüência natural da estrita analogia entre o fluxo de informação delineado pelo Dogma Central da Biologia Molecular, e o fluxo de informações através de um sistema de comunicação, como modelado por Shannon. Este foi também o ponto de partida para a utilização sistemática de ferramentas orientadas pela Teoria da Informação para descobrir muita coisa interessante do ponto de vista biológico (Segal, 2003; Fabris, 2009). Na realidade, a idéia de um "código genético", experimentalmente demonstrada deste os anos 60, só reforçava esta visão. A biologia molecular, desde então, foi inundada pelo jargão informacional.
O Dogma Central da Biologia Molecular é o ápice deste linguajar já que se propõe a descrever o fluxo de “informação biológica", que iria do DNA em direção às proteínas, no sentido de que o DNA, passando pelo RNA, através dos processos de transcrição e tradução, impulsionando a síntese das proteínas, carregaria, assim, a informação hereditária do genótipo para o fenótipo.
Então, ao analisarmos a questão por esta perspectiva, uma analogia óbvia se segue: o fluxo de informação que, começa a partir do DNA e atinge as proteínas, que flui através dos sistemas biológicos de comunicação (descritos pelo Dogma Central), é análogo ao fluxo de informaçãos que tem início a partir da "fonte" e que atinge o "receptor" (no outro lado do canal) como acontece nos sistemas de comunicação descrito por Shannon (Fabris, 2009).
“Nessa metáfora o DNA, que é uma seqüência de nucleotídeos chamados adenina, timina, citosina e guanina (A, T, C, G), é interpretado como uma seqüência baseada em um alfabeto de 4 letras, enquanto que uma proteína, que é um seqüência baseada em 20 aminoácidos (metionina, serina, treonina etc.), é interpretada como uma seqüência do alfabeto de 20 letras.” (Fabris, 2009)
Como sugere Fabris (2009), esta abordagem abre a possibilidade de que a Teoria da Informação (TI) seja usada na construção de um modelo transmissão de informação biológica e de sua correção. Porém, existem certos problemas com esta idéia. O primeiro deles está nos vários sentidos em que a palavra “informação” é usada tanto na nossa linguagem coloquial, quando no jorgão científico. Há diferenças no uso deste termo, em seu sentido técnico-matemático empregado pelos físicos, matemáticos, cientistas da computação e engenheiros, de um lado, e a forma mais heurística empregada por biólogos e outros biocientistas, de outro lado. Neste segundo caso, é o papel analógico do termo “informação” que é mais forte (assim como a referência ao “conteúdo semântico” informacional dos sistemas biológicos, mas próximo a linguagem coloquial).

A figura acima ilustra como a teoria da informação pode ser associada com o "fluxo de informação molecular " dentro da célula. Como explica o filósofo Paul E. Griffths, a informação flui através de um canal interligando dois sistemas, uma fonte que contém a informação e um receptor, que seria o sistema sobre o qual a informação diz respeito. Existe um canal entre dois sistemas quando o estado de um está causalmente ligado, de forma sistemática, ao estado do outro, de modo que o estado da fonte pode ser descoberto através da observação do estado do receptor. O conteúdo informacional causal de um sinal é simplesmente o estado de coisas correlacionadas de forma confiável com a outra extremidade do canal. Assim, “o fumo traz informações sobre fenótipos de fogo e doenças levar informações sobre os genes da doença.” (Griffiths, 2001)
Enquanto esta relação pode ser facilmente aplicada ao DNA codificante e aos biopolímeros, RNAs e proteínas (transcritos e traduzidos durante o processo de leitura destes genes) e, portanto, pode ser defendida como não-problemática (dando, assim, um sentido mais claro a idéia de informação genética, neste contexto limitado), o mesmo não pode ser dito para as relações entre os genes e o desenvolvimento, no qual a própria idéia de um programa ou de uma relação causal direta, torna-se cada vez mais difícil de defender, a não ser como uma metáfora, útil em determinadas situações, mas problemática em outras. Aqui o discurso de informação genética perde o seu rigor potencial e não é mais capaz de resistir àquilo que Griffiths chama de tese de paridade, que basicamente considera que diversos outros “recursos” da matriz desenvolvimental, que incluem o ambiente, padrões de metilação e condensação da cromatina, etc podem também ser fontes de informação tirando qualquer exclusividade dos genes, entendidos como seqüências de DNA codificadoras de biopolímeros. (Griffiths, 2001).
Seguindo a análise de Godfrey-Smith (2007), o ponto importante é que quando um biólogo usa o conceito de informação neste sentido mais estrito (causal, correlacional, sintático) como uma descrição da ação de genes ou de outros processos, em um dado contexto, ele ou ela não está introduzindo um novo tipo de relação especial ou propriedade, como tentam fazer crer os criacionistas ao usarem suas versões superficiais e mistificadas de informação. Este tipo de uso, empregado por biocientistas, consiste apenas na adoção de uma abordagem quantitativa particular para descrever as correlações normais ou conexões causais entre certos sistemas biológicos.
Tendo isso em mente, torna-se claro que a aplicação do conceito de informação pode ir além da metáfora e da analogia, ao incorporar os métodos, idéias e ferramentas da TI para obter informações sobre as regularidades estatísticas dos dados obtidos a partir de seqüências biológicas de nucleotídeos ou aminoácidos. Estas aplicações existem e têm crescido cada vez mais, assim como tentativas mais ambiciosas de interpretar os sistemas biológicos, e sua “lógica” particular, usando a teoria da informação de Shannon e a teoria da informação algorítmica de Kolmogorv e Chaitin. Porém, as aplicações destes modelos teóricos em outras áreas como na biologia do desenvolvimento por exemplo, ainda são alvo de muitas críticas (veja Sarkar, 1996 e 1999; Griffths, 2001, Godfrey-Smith, 2007), diferentemente das abordagens que se concentram nas seqüencias e em seus produtos imediatos as proteínas, como a biologia e evolução molecular, que são cada vez mais valorizadas.
Esta aproximação entre as ciências exatas é mais notável em áreas híbridas como a biofísica, bioinformática (e biologia computacional) e na biomatemática, todas áreas com interfaces com a biologia molecular e com a biologia evolutiva.
A teoria da informação de Shannon:
Antes de adentrarmos neste ramo da matemática que eu mesmo conheço pouco (mas que serei assistido por ótimos tutoriais e fontes bibliográficas, especialmente as disponibilizadas pelo grupo do biólogo teórico Thomas D. Schneider no site de seu laboratório do NCI (National Cancer Institute), é preciso contextualizar um pouco a história e conhecermos os interesses desta figura lendária nas ciências, chamada de Claude Shannon.

Shannon, na época trabalhando nos laboratórios Bell (na época uma divisão da “Telephone and Telegraph Company”, AT&T), objetivava responder a seguinte questão:
“O que a ATT&T vendia exatamente?”
ou de um jeito mais técnico
“Como a informação pode ser definida com precisão?”
A teoria da Informação e Shannon:
"A informação é medida como a diminuição da incerteza de um receptor (ou uma máquina molecular) ao ir do estado “antes” para o estado “depois”. " (Schneider, 2010)
A teoria da informação é um ramo da matemática iniciado nos trabalhos de Claude Shannon na década de 1940. A teoria aborda alguns aspectos muito importantes da comunicação, tais como:
"Como podemos definir e medir a informação?",
"É possível se comunicar de forma confiável a partir de um ponto a outro, se só temos um canal de comunicação ruidosos?" (Schneider, 2010),
"Como pode o conteúdo de informação de uma variável aleatória ser medido?" (Schneider, 2010)
e
"Qual é o máximo de informações que podem ser enviados através de um canal de comunicação?" (Capacidade do canal) (Schneider, 2010).
Shannon fez isso de uma forma muito rigorosa. Primeiro estabeleceu vários critérios uteis para que se pudesse definir “informação” de forma precisa, e, em seguida, mostrou que apenas uma fórmula satisfaria estes critérios. Esta resposta, imediatamente levantou outra questão:
“Quanta informação pode ser enviada como os equipamentos existentes, as nossas linhas de telefone?”
Shannon, então, desenvolveu a teoria da capacidade do canal para responder a esta questão (Schneider, 2006).
A capacidade do canal, C, é dada em bits por segundo e depende de apenas três fatores: a potência, P, do sinal no receptor, o ruído, N, perturbando o sinal do receptor, e a largura de banda, W, que é o intervalo de freqüências utilizadas na comunicação:
C = W log2((P/N) + 1) bits por segundo.
Então, caso se deseje transmitir alguma informação a uma taxa R (também em bits por segundo, b/s), um dos resultados demonstrados por Shannon é que quando a taxa excede a capacidade (R> C), a comunicação falhará e no máximo C b/s serão transmitidos. A analogia usada por Schneider (2006) é a seguinte:
“...colocar água através de um tubo. Existe um limite máximo para o quão rápido a água pode fluir, em algum momento, a resistência no tubo irá evitar novos aumentos ou o tubo irá estourar.”
Mas o resultado mais surpreendente ocorre quando a taxa, R, é menor ou igual à capacidade do canal (R ≤ C). Shannon provou matematicamente, que neste caso, é possível transmitir a informação com tão poucos erros quanto desejado [Schneider, 2006 ].
“O erro é o número de símbolos errados recebidos por segundo. A probabilidade de erros pode ser pequena, mas não pode ser eliminada. Shannon assinalou que a maneira de reduzir os erros é codificar as mensagens no transmissor/fonte para protegê-las contra o ruído e, em seguida, decodificá-las no receptor para remover o ruído. A clareza das telecomunicações modernas, CDs, MP3s, DVDs, sistemas sem fio, telefones celulares, etc, surgiu porque os engenheiros têm aprendido como fazer circuitos elétricos e programas de computador que fazem esta codificação e decodificação. Porque eles se aproximam do limite de Shannon, os códigos desenvolvidos recentemente prometem revolucionar as comunicações novamente fornecendo maior transmissão de dados através dos mesmos canais [10] [11].” [Schneider, 2006 ]
Informação e bits:
Um outro conceito inevitável quando passamos a adotar as definições mais rigorosas de informação é o conceito de "bit". Suponha que você jogue uma moeda um milhão de vezes e anote a seqüência de resultados. Se você deseja comunicar essa seqüência para outra pessoa, quantos bits você iria precisar? Se for uma moeda justa, isto é não-viciada, os dois resultados possíveis, caras e coroas, ocorrem com igual probabilidade. Por isso, cada jogada requer 1 bit de informação para se transmitida. Para enviar toda a seqüência, é necessário um milhão de bits. Agora, imagine que esta moeda é viciada, assim, cada “cara” ocorre apenas uma em cada quatro vezes, e “coroas” o resto das vezes (3/4). Neste caso, em particular, 811,300 bits seriam suficientes para a mensagem pudesse ser enviada, o que parece implicar que cada face da moeda exige, para que possa ser transmitida, apenas, 0,8113 bits. Óbvio, você não pode transmitir um jogada de moeda com menos de um único bit, em um idioma só de “zeros” e “uns”. Não obstante, se o objetivo é transmitir uma seqüência de jogadas, e a distribuição destas jogadas é enviesada, de alguma forma, então, você pode usar seu conhecimento da distribuição probabilística em questão para selecionar uma forma de codificação mais eficiente (Touretzky,2004).
Em seu tutorial sobre a teoria da informação Touretzky (2004):
“Suponha que a moeda é fortemente tendenciosa, de modo que as probabilidades de conseguir cara é de apenas 1/1000 e coroa é 999/1000. Em um milhão de lançamentos desta moeda seria de se esperar ver apenas cerca de 1.000 caras. Ao invés de transmitir os resultados de cada lance, nós poderíamos apenas transmitir os números de arremessos que resultaram em caras, o resto dos lances poderia ser considerado como coroas. Cada lance tem uma posição na seqüência: um número entre 1 e 1000000. Um número

nesse intervalo pode ser codificado usando apenas 20 bits. Então, se nós transmitimos 1.000 números de 20 bits, teremos todo o conteúdo original de informação da seqüência de um milhão de arremessos transmitidas, usando apenas cerca de 20.000 bits. (Algumas seqüências conterão mais de mil caras, e algumas menos, de modo que para ser perfeitamente correto, devemos dizer que esperaríamos necessitar de, em média, 20 mil bits para transmitir uma seqüência dessa maneira.)
Nós podemos fazer ainda melhor. Codificar as posições absolutas das caras na seqüência gasta 20 bits por cara, mas nos permite transmitir as caras em qualquer ordem. Se concordarmos em transmitir as caras de forma sistemática, percorrendo a seqüencia do início ao fim, então ao invés de codificar suas posições absolutas podemos apenas codificar a distância até o próxima “cara”, o que demandaria menos bits. Por exemplo, se os quatro primeiros cabeças ocorreram nas posições 502, 1609, 2454 e 2607, então a sua codificação, como distância para o próximo “cara", seria 502, 1107, 845, 153. Em média, a distância entre duas “caras” será cerca de 1.000 arremessos, e só raramente a distância será superior a 4.000 jogadas. Números na faixa de 1 a 4000 pode ser codificado em 12 bits. (Nós podemos usar um truque especial para lidar com os casos raros em que as cabeças são mais de 4.000 aletas distante, mas não vamos entrar em detalhes aqui.) Assim, usando essas convenções de codificação mais sofisticadas, a seqüência de um milhão de lançamentos de moeda com cerca de 1.000 “caras” podem ser transmitidas com apenas 12 mil bits, em média. Assim, um único lance de moeda precisa de apenas 0,012 bits para ser transmitido. Mais uma vez, esta alegação só faz sentido porque na verdade estamos transmitindo toda uma seqüencia de jogadas. " (Touretzky, 2004)
A partir desta explicação Touretzky ( 2004) lança algumas questões:
"E caso inventássemos uma codificação mais inteligente?
Qual é o limite para eficiência de qualquer codificação?
O limite estaria por volta de 0,0114 bits por lançamento, então já estamos muito perto da codificação ideal. "
O ponto central aqui, portanto, é que, o dito, conteúdo informacional de uma seqüência é definido como o número de bits necessários para transmitir essa seqüência usando algum tipo codificação ótima. Claro, sempre, é possível, entretanto, utilizarmos um código menos eficiente, o que exigirá mais bits. Porém isso não aumenta a quantidade de informação transmitida (Touretzky, 2004).
Informação e Incerteza:
Informação e incerteza são ambos termos técnicos que podem descrer qualquer processo que seleciona um ou mais objetos de um conjunto de objetos. Estas medidas não medem nada que lide com o significado ou outras características implicadas, às vezes, pelo termo “informação”, mesmo porque, até hoje, ninguém mostrou como fazê-lo matematicamente de forma efetiva. Seguindo um exemplo dado por Tom Schneider:
“Suponha que tenhamos um dispositivo que possa produzir três símbolos: A, B ou C. Enquanto esperamos o próximo símbolo, não temos certeza de qual o símbolo irá ser produzido. Uma vez que o símbolo aparece e o vemos, a nossa incerteza diminui, e que sinalizamos que recebemos alguma informação. Ou seja, a informação é a diminuição da incerteza. Como deve ser medida a incerteza? A maneira mais simples seria dizer que temos um grau de incerteza "de 3 de símbolos". Isso funciona bem até que começamos a assistir a um segundo dispositivo, ao mesmo tempo que, imaginemos, produz símbolos 1 e 2. O segundo dispositivo nos dá um grau de incerteza "de dois símbolos". Se combinarmos os dispositivos em um único dispositivo, existem seis possibilidades, A1, A2, B1, B2, C1, C2. Então, isso quer dizer que este dispositivo tem um grau de incerteza "de 6 de símbolos". Aí, vemos o primeiro problema. Esta não é a maneira que nós geralmente pensamos sobre informação. Por exemplo, se recebemos dois livros, nós preferíamos dizer que recebemos duas vezes a informação de um único livro. Ou seja, gostaríamos que os nossos medida fosse aditiva. ”
Podemos, entretanto, tornar esta medida aditiva, ao usarmos o logaritmo do número de símbolos possíveis. Ao empregarmos este “truque” poderemos adicionar os logaritmos, ao invés de multiplicar os número de símbolos. Assim, voltando ao exemplo de Schneider, o primeiro dispositivo nos deixaria em um estado de incerteza equivalente ao log (3), o segundo ao log (2) e os dois dispositivo combinados: log (3) + log (2) = log (6). Então, como explica Schneider:
“A base do logaritmo determina as unidades. Quando usamos a base 2 as unidades estão em bits (base 10 nos dá digits, a dos logaritmos naturais, nos dá nats [14] ou nits [15]). Assim, se um dispositivo produz um símbolo, temos a certeza de log 2( 1 )= 0 bits, assim não temos incerteza sobre o que o dispositivo irá fazer em seguida. Se ela produz dois símbolos nossa incerteza seria log2 (2) = 1 bit. Ao ler um mRNA, caso o ribossomo encontre qualquer um das quatro bases igualmente prováveis, então a incerteza é de 2 bits.”
A fórmula para a incerteza, que é log2 (M), com M sendo o número de símbolos, pode ser estendida, de forma que ela possa lidar com casos em que os símbolos não são igualmente prováveis:
“Por exemplo, se existem 3 símbolos possível, mas um deles nunca aparece, então a nossa incerteza é 1 bit. Se o terceiro símbolo aparece raramente, em relação aos outros dois símbolos, a nossa incerteza deve ser um pouco maior do que 1 bit, mas não tão elevada como log2 3 bits.”
Reorganizando a fórmula temos:

de modo que P = 1/M é a probabilidade de que qualquer símbolo apareça.
Generalizamos isso para as várias probabilidades dos símbolos Pi, de modo que as probabilidades somem 1, no total, o que equivale ao 100%, no jargão popular:

[Lembre-se que o símbolo, SOMATÓRIO significa adicionar todos os Pi , para i começando em 1 e terminando em M.] A surpresa que temos quando vemos o iésimo tipo de símbolo foi chamada, “surprisal” por Tribus, e é definida por analogia com - log2 P para ser

Por exemplo, se Pi aproxima-se de 0, ficaríamos muito surpresos ao descobrir qual é o iésimo símbolo (pois este quase nunca deveria aparecer), então, pela fórmula, ui aproxima-se de ∞. Por outro lado, se Pi =1, então, não haveria surpresa alguma ao nos deparamos com o iésimo símbolo (pois este sempre deveria aparecer), ui = 0.
“Incerteza é o surprisal médio para a seqüência infinita de símbolos produzidas pelo nosso aparelho. Por ora, vamos, vamos encontrar a média para uma seqüência de símbolos de comprimento N, que tenha um alfabeto de M símbolos. Suponhamos que o tipo do iésimo símbolo apareça Ni vezes de modo que se somarmos através de toda a cadeia e juntarmos os símbolos, então isso é o mesmo que somarmos através dos símbolos: ”

Existirão Ni casos em que temos surprisal ui . O surprisal médio dos símbolos N é:

Substituindo N pelo denominador e trazendo-o para dentro do somatório de cima, obtemos:

Se fizermos esta medida para uma seqüência infinita de símbolos, então a freqüência Ni/N torna-se Pi, a probabilidade do iésimo símbolo. Fazendo essa substituição, vemos que o nosso surprisal médio (H) seria:

Finalmente, substituindo ui, obtemos a famosa fórmula geral de Shannon para a incerteza:

“Shannon chegou a esta fórmula por um caminho muito mais rigoroso do que nós, a partir da postulação de várias propriedades desejáveis para a incerteza, para, em seguida, derivar a função. Esperemos que o caminho que seguimos apenas lhe de uma sensação de como funciona a fórmula.” (Schneider, 2010)
Para ver como a função H parece, podemos traçá-la para o caso de dois símbolos:

A curva é simétrica, e atinge o máximo quando os dois símbolos são igualmente prováveis (probabilidade = 0.5). Cai a zero sempre que um dos símbolos torna-se dominante em detrimento dos outros símbolos. A entropia de Shannon (incerteza) pode ser interpretada como a medida média da informação (a-posteriori) fornecida pela fonte, ou a incerteza (a priori) média associada à saída da fonte.
Schneider propõe o seguinte exercício:
“Como um exercício instrutivo, suponha que todos os símbolos são igualmente prováveis. Ao que a fórmula para H (equação (8)) se reduz? Você pode querer experimentar por si mesmo antes de a ler. "
Igualmente provável significa que Pi = 1/M, por isso, se substituir isto na equação da incerteza temos:

Uma vez que M não é uma função de i, podemos retirá-lo do somatório:

é a exatamente a equação simples com a qual nós começamos. Pode ser mostrado que para um determinado número de símbolos (ou seja, quando M é fixo), que a incerteza H tem seu maior valor somente quando os símbolos são igualmente prováveis. Por exemplo, uma moeda imparcial é mais difícil de adivinhar os seus resultados do que uma moeda tendenciosa.
Aqui está um exemplo. Suponha que temos M = 4 símbolos:

Com probabilidades (Pi):

Estes possuem surprisals (-Log2Pi):

Então, a incerteza é

O que significa dizer que um sinal tem 1,75 bits por símbolo? Isso significa que podemos converter o sinal original em uma seqüência de 1's e 0's (dígitos binários), de modo que, em média, existem 1,75 dígitos binários para cada símbolo no sinal original. Alguns símbolos terão mais dígitos binários (os mais raros) e outros terão menos (os mais comum).
Ao re-codificar para que o número de dígitos binários seja igual ao surprisal:

Desta forma, a cadeia ACATGAAC cujas letras aparecem nas mesmas freqüências que as probabilidades definidas acima, passa ser codificada como 10110010001101 , onde 14 dígitos binários são utilizados para codificar oito símbolos, assim a média é de 14/8 = 1,75 dígitos binários por símbolo (Schneider, 2006 e 2010). Este é o chamado de “código de Fano”. Este tipo de código têm a propriedade que você pode decodificá-los sem a necessidade de que existam espaços entre os símbolos. Normalmente, é preciso saber o quadro de leitura, mas neste exemplo pode-se descobrir. Neste particular codificação (equações (16)), o primeiro dígito binário distingue entre o conjunto que contém A, (simbolizado por {A}) e o conjunto (C, G, T), que são igualmente prováveis já que 1/2 = 1/4 + 1/8 + 1/8. O segundo dígito,usado caso o primeiro dígito seja 0, distingue C de G, T. O dígito final distingue G de T. Como cada escolha é igualmente provável (no nosso definição original das probabilidades dos símbolos), cada dígito binário neste código carrega um bit de informação. Cuidado! Isso nem sempre será verdade. Um dígito binário pode fornecer um bit apenas se os dois conjuntos representados pelos dígito forem igualmente prováveis (como ajustado para este exemplo). Se eles não têm a mesma probabilidade, um dígito binário fornece menos de um bit. (Lembre-se que H é máxima quando as probabilidades são iguais.) (Schneider, 2006 e 2010) Então, caso as probabilidades fossem:

Não há nenhuma maneira de atribuir um código (finito) de modo que cada dígito binário tenha o valor de um bit (usando grandes blocos de símbolos, pode-se aproximar deste ideal). No exemplo ajustado, não há maneira de usar menos de 1,75 dígitos binários por símbolo, mas poderíamos esbanjar e usar dígitos extras para representar o sinal. O código de Fano funciona razoavelmente bem ao dividir os símbolos em grupos sucessivos que têm a mesma probabilidade de ocorrer (Schneider, 2010). A medida da incerteza, portanto, nos diz o que é possível obter em uma situação ideal de codificação, assim, revelando-nos o que é impossível, como, por exemplo, enviar o sinal com 1,75 bits por símbolo codificado utilizando-se apenas um dígito binário por símbolo (Schneider, 2010).
Como assumiu-se que a informação é a diminuição da incerteza, e agora que temos uma fórmula geral para a incerteza, podemos expressar a informação usando-a:
Schneider (2010) adota o termo "flip-flop para evitar o uso da palavra "bit" enquanto discute a codificação de Fano já que há dois significados para essa palavra:
1. Um dígito binário, 0 ou 1. Só podendo ser um inteiro. Estes "bit" são as partes individuais de dados em computadores.
2. Uma medida de incerteza, H ou R. Esta informação pode ser qualquer número real porque é uma média.
É a medida que Shannon utilizado para discutir sistemas de comunicação.
Suponha que um computador contém alguma informação em sua memória. Se estivéssemos a olhando cada flip-flop (os equivalente físicos das possibilidade binárias na memória do computador), teríamos uma incerteza de Hantes bits por flip-flop. Imagine, então, que agora limpamos parte da memória do computador (ao definir os valores como zero), de modo que há uma nova incerteza, menor do que o anterior: Hdepois.
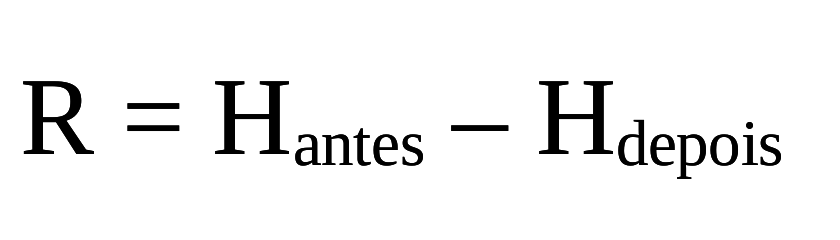
Então, a memória do computador perdeu uma média de R= Hantes - Hdepois bits de informação por flip-flop. Se o computador fosse completamente limpo, então Hdepois= 0 e R = Hantes . Agora considere um teletipo recebendo caracteres de uma linha telefônica. Se não houvesse ruído na linha telefônica e nenhuma outra fonte de erro, o teletipo imprimiria o texto perfeitamente. Com o ruído, entretanto, há alguma incerteza sobre se um caractere impresso é realmente o caractere que foi realmente enviado. Portanto, antes de um caractere ser impresso, o teletipo deve estar preparado para qualquer um dos caracteres possíveis, e este estado preparado tem incerteza Hantes , depois que cada caractere tenha sido recebido, ainda há incerteza, Hdepois. Esta incerteza é baseada na probabilidade de que o símbolo que foi recebido através da linha não seja igual ao símbolo que foi enviado, e mede a quantidade de ruído (Schneider, 2010).
Usando o próprio exemplo de Shannon, como relatado por Schneider (2010):
“Um sistema com dois símbolos igualmente prováveis transmitindo a cada segundo envia a uma taxa de 1 bit por segundo sem erros. Suponha que a probabilidade de que um 0 seja recebido quando um 0 é enviado é de 0,99 e a probabilidade de um 1 é recebido 0,01. "Estes valores são invertidos se 1 é recebido." Então, a incerteza após recebimento de um símbolo Hdepois = -0,99 log2 0,99 - 0,01log2 0,01 = 0,081, de modo que a taxa real de transmissão é R = 1- 0,081 = 0,919 bits por segundo. A quantidade de informação que recebe através é dada pela diminuição da incerteza, a equação (20). ”
Schneider (2010) prossegue:
“Infelizmente muitas pessoas têm cometido erros porque não compreendem esse ponto claramente. Os erros ocorrem porque as pessoas assumem implicitamente que não há ruído na comunicação. Quando não há ruído, R = Hantes, como com a memória de um computador completamente apagada. Isto é, se não há ruído, a quantidade de informações transmitidas é igual à incerteza antes da comunicação. Quando há ruído, e alguém assume que não há nenhuma, isso leva a todos os tipos de filosofias confusas. Deve-se sempre levar em conta o ruído. ”
Aplicando o conceito de informação de Shannon à biologia molecular:
As idéias e modelos de Schneider e de outros pesquisadores buscam (entre outras coisas) inserem-se na investigação das possibilidades da nanotecnologia, isto é, a construção de máquinas com precisão na escala atômica. A biologia fornece muitos exemplos de que como fazer isso já que sistemas formados por biomacromoléculas (que alguns chamam de "máquinas moleculares") evoluíram nos seres vivos, servindo de exemplos a serem copiados.
Os trabalhos de Schneider com a teoria da informação molecular e a teoria das máquinas moleculares investigam exatamente quais são as limitações destes sistemas biomoleculares e assim objetivam compreender:
“O que deveríamos tentar e o que seria tolice tentar violar?”
A teoria das máquinas moleculares se divide em três níveis hierárquicos:
Schneider usa medida de informação de Shannon para caracterizar com precisão a conservação da seqüencia de nucleotídeos nos sítios de ligação. Os métodos desenvolvidos por Schneider substituem a utilização de seqüencias de consenso, segundo o próprio Schneider, proporcionando assim melhores modelos para biólogos moleculares.
Em seus estudos foi detectado um excesso de conservação da seqüencia de promotores do bacteriófago T7 e nas repetições InCD do plasmídeo F, o que levou o grupo de Schneider a prever a existência de proteínas que se ligam ao DNA nestes sítios. As previsões provenientes do teorema da capacidade do canal (do qual avanços tecnológicos como a extrema à incrível fidelidade dos CD e DVDs e das comunicações telefônicas, podem ser traçadas diretamente), quando re-derivadas para a biologia molecular, explicam a precisão surpreendente de muitos eventos moleculares. E, através, de conexões com segunda Lei da Termodinâmica e com a idéia do Demônio de Maxwell, essa abordagem também tem implicações diretas sobre o desenvolvimento da nanotecnologia (Scneider, 1995).

Schneider divide a teoria em três níveis, que são caracterizadas pelos seguintes tópicos:
Nível 0. Logos de Seqüência: padrões em seqüências genéticas.
Nível 1. Capacidade de Máquina: Energética de macromoléculas.
Nível 2. A Segunda Lei: Demônio de Maxwell, e os limites dos computadores.
No nível 0 da teoria das máquinas moleculares analisa-se os sistemas de controle da expressão gênica através de elementos Cis- e como pode-se utilizá-los para investigar os processos de informação ao nível molecular.
No nível 1 da teoria [Schneider, 1991] são explicadas a atividade incrivelmente precisa dessas moléculas:
Por exemplo, a enzima de restrição EcoRI 'varre' a dupla hélice de DNA (material genético) e corta, quase exclusivamente, ao encontrar o padrão 5 'GAATTC 3', evitando a 46- 1. = 4.095 pares de base de outras seis longas seqüências [Polisky et al, 1975 Woodhead et al. 1981, Pingoud, 1985]. Como EcoRI é capaz de fazer isto era, de certa forma, um mistério porque as explicações químicas convencionais falharam [Rosenberg et al. 1987]. De acordo com o nível 1 da teoria, máquinas moleculares tais como a EcoRI estão limitadas nas suas operações por sua “capacidade da máquina”, que está intimamente relacionada à famosa “capacidade do canal” Claude Shannon [Shannon, 1949]. Assim, desde que não se exceda a capacidade do canal, o teorema de Shannon

garante que, os erros na comunicação sejam tão poucos como desejado. É esse teorema que levou às comunicações telefônicas e gravações de som em CD espetacularmente claras. A alegação equivalente para máquinas moleculares é que, enquanto uma máquina molecular não exceda sua "capacidade de máquina", ela pode agir tão precisamente quanto possa ser necessário para a sobrevivência evolutiva (Schneider, 1994 nano).
O nível 2 da teoria [Schneider, 1991] lida com o antigo problema do demônio de Maxwell [Leff & Rex, 1990] e mostra que existe um custo energético para as operações molecular medido em joules que deve ser dissipado, para o meio, para cada bit de informação adquirida pela máquina, e este custo seria de, pelo menos, joules, onde é a constante de Boltzmann e T é a temperatura em kelvin. Porém, segundo Schneider, na literatura recente, alguns autores afirmam que muitas vezes não é um limite em tudo ou que a perda de informações (ao invés de ganho) é que estaria associada com a dissipação [Landauer, 1991]:
"No entanto, essa relação é apenas (!) uma reafirmação da Segunda Lei da Termodinâmica [Schneider, 1991], então aqueles que a contestam tem poucas chances de estarem corretas.”
Nível 0 E entram os logos de seqüencia:
Para compreendermos a importância do logos de seqüencia primeiro é preciso que compreendamos como se dá o controle da expressão gênica. Normalmente este controle é exercido por proteínas e outras macromoléculas ("identificadores") que se ligam à seqüências especificas nas moléculas de DNA ou RNA. A forma tradicional de caracterizar estas seqüências envolve a utilização de "seqüência de consenso" em que a base mais freqüente, entre as diversas variantes existentes, é escolhida para cada posição do sítio de ligação. Porém, com esta abordagem a informação sobre as freqüências de cada variante de posição é perdida, assim este método destrói padrões sutis existentes nos dados. Esta perda de dados inviabiliza a tarefa de modelagem de seqüencias/sítios de ligação. A Fig. 1 mostra as seqüências nas quais as proteínas cI e cro ligam-se no DNA do bacteriófago e abaixo destes está um logo de seqüência.
Ao analisarmos a figura B, na posição -7, por exemplo, percebe-se que ali encontramos sempre um A em cada um dos 12 sítios de ligação, que é representado como um A 'bem alto' no logo. Já na posição 8 encontramos a maioria de Ts, além de 2 Cs e um A, o que é representada por uma pilha de letras, com a altura de cada letra proporcional à sua freqüência, além de ordenadas de uma maneira que a mais freqüente fique na parte superior. A altura total da pilha é a conservação da seqüencia naquela posição, medida em bits de informação. Lembrando que um "bit" é uma escolha entre duas possibilidades igualmente prováveis. As quatro bases do DNA podem ser dispostas formando um quadrado:
A C
G T
Para escolher um dos 4 nucleotídeos é preciso apenas responder sim e não para duas perguntas: "É em cima?" e "É na esquerda?". Assim, a escala para o logo de seqüência vai de 0 a 2 bits. Quando as freqüências das bases não são exatamente 0, 50 ou 100 por cento, um cálculo mais sofisticado deve ser feito. A incerteza é uma função da freqüência f (b; l) de cada base b na posição l de cada um na base b

onde (n (l)) é uma correção para o pequeno tamanho da amostra n na posição l. O conteúdo da informação (ou conservação) seqüência é então:

O logo de seqüência não mostra apenas as freqüências originais das bases, mas também mostra a conservação em cada posição nos sítios de ligação. A partir do gráfico de logos de seqüencia pode-se ver imediatamente o padrão dos locais de ligação. Porém, ao olhar a seqüencia de consenso, em contraste, de seqüência, é possível ser enganado pelas distorções desta representação em que, por exemplo, não se pode distinguir 100% A de 75% A.
A conservação de seqüencias é medida usando-se bits de informação, especialmente por que eles são aditivos (lembre-se dos logaritmos). Assim, pode-se obter a conservação da seqüencia total do sítio de ligação simplesmente somando as alturas das pilhas dos logos de seqüência:

Porém, o reconhecedor deve selecionar os sítios de ligação de todas as possíveis seqüências do material genético, então para que possamos calcular quantos bits de escolhas que o reconhecedor faz é preciso determinar o tamanho do material genético G e o número de sítios de ligação γ. Antes que o sítio seja localizado, o número inicial de bits de escolha é log2 G, após o conjunto de sítios ter sido encontrado restam log2 γ escolhas que não foram feitas. Diminuindo, então, a incerteza nas medidas do número de escolhas feitas:

O nome Rfrequência foi escolhido porque γ/G é a freqüência dos sítios e este número se aproxima do valor da
Rsequência, o que significa que o conteúdo de informação nos padrões dos sítios de ligação é apenas o suficiente para que os sítios sejam encontrado no genoma.
“Matt Yarus sugeriu uma analogia simples que deixa isso claro. Se temos uma cidade com 1.000 casas, qual o número de dígitos que devemos colocar em cada casa para garantir que a correspondência seja entregue corretamente? A resposta é de 3 dígitos já que as casas podem ser numeradas de 000 a 999. Portanto, há uma relação entre o tamanho da cidade (tamanho do material genético e do número de sítios) e os dígitos na caixa de correio (padrão dos sítios de ligação).” (Schneider, 1994)
Uma das aplicações mais interessantes desta abordagem envolveu aquilo que parecia ser uma surpreendente exceção, no caso do promotores do bacteriófago T7, a Rseqüência = 35,4 ±2 bits por sítio, mas Rfreqüência = 16,5 por sítio, o que deixava um Rseqüência/ Rfreqüência = 2,01 ± 01 vezes de excesso de conservação da seqüencia (Schneider, 1989, 1994, 1996). Isso, indicaria ou que a teoria estava errada ou que algo interessantes estava acontecendo ali. Schneider afirma:
“Na analogia da cidade, há 1.000 casas, mas cada casa tem 6 dígitos. Uma explicação é que existem dois sistemas independentes de entrega de correio que não poderiam concordar com um sistema de endereços comuns. A explicação biológica é que existem duas proteínas de ligação a esses dois padrões de seqüencias. Nós já sabemos sobre um deles, é o da RNA polimerase T7. Para testar essa idéia, um grande número de seqüências de DNA aleatórias foram construídas e, em seguida, foram selecionadas as que ainda funcionavam como promotores T7[8]. Se houvesse uma outra proteína, então ela não se ligaria nesse teste e assim o excesso de informações desapareceria. Isso foi realmente o que aconteceu (Fig.2 abaixo): os sítios de ligação para os promotores T7 sozinhos só tem 18,2 bits de informação, próximo ao valor previsto de Rfreqüência = 16,05 bits por sítio. A hipótese de que existe uma segunda proteína foi confirmada, mas até agora esta não foi identificada experimentalmente. ” (Schneider, 1994)
Mais tarde, o grupo de Schneider descobriu outro caso, desta vez no plasmídeo-F InCD na qual a Rseqüência,=
60,2±2,06 bits por sítio e a Rfreqüência = 19,06 bits por sítio, de modo que, havia um excesso de Rseqüência/Rfreqüência = 3,07 ± 0,13 vezes de conservação da seqüencia. Foi descoberto que três proteínas ligam-se a esta região do DNA, e foram provisoriamente capazes de identificá-las (Schneider, 1994, 1996) .
Na figura à esquerda, na porção superior A, podemos observar os logos de seqüencia para o sítio de ligação da RNA polimerase do bacteriófago T7 e logo abaixo em B, o logo de seqüencias como os padrões indispensáveis para que a ligação da RNA polimerase ligue-se ao DNA e funcione, mostrando que as seqüencias excedentes realmente são sítios de ligação para uma proteína desconhecida,explicando o excesso de informação revelado pela (Rseqüência/Rfreqüência = 2,01 ±01) de mais de 2 vezes em relação ao esperado caso os padrões de revelado em A fossem de um único sítio para aRNA polimerase (Schneider, 1994, 1996).
Nível 1. Capacidade de Máquina: Energética de macromoléculas:
Esses resultados mostram que é possível aplicar, com sucesso, as idéias da teoria da informação nas interações moleculares, o que sugere que outros conceitos da teoria da informação podem também serem aplicados. Um desses outros conceitos, aliás muito importante, é o de 'capacidade do canal'. Um dado canal de comunicação, como um sinal de rádio, vai operar durante um certo intervalo de freqüências W e o sinal irá dissipar alguma potência P no receptor. O receptor deve distinguir o sinal do ruído térmico N que também está recebendo. Shannon considerou que esses fatores sozinhos define a maior taxa de informações que pode passar através do canal:

Shannon também provou um teorema notável sobre a capacidade do canal, que demonstra que caso a taxa R de comunicação seja maior do que a capacidade, no máximo C bits por segundo irão passar. Por outro lado, se , a taxa de erro pode tornada tão pequena quanto desejado, mas nunca zero. A maneira de fazer isso é codificar o sinal para protegê-lo do ruído de modo que quando o sinal é decodificado, erros possam ser corrigidos.
“A codificação é usada em discos compactos para corrigir erros de até 4000 bits simultâneos [11], razão pela qual música do CD é tão clara. As idéias correspondentes podem ser usadas para interações moleculares em que uma molécula (“máquina molecular”) faz 'escolhas' entre diversas possibilidades [12, 4]. A formulação correspondente do teorema é que, enquanto a máquina molecular não exceda a capacidade da máquina, as interações moleculares podem ser tão pequenas quanto o mínimo necessário para garantir a sobrevivência do organismo. Claro 'formulações' não pode ser sobre os “desejos” na biologia molecular, o teorema é relacionado à evolução do sistema. Este resultado matemático explica a precisão observada dos sistemas controle genético.”(Schneider, 1994)
A capacidade da máquina é o conceito análogo ao de capacidade do canal e a transposição do teorema homônimo de Shannon para as máquinas moleculares Assim, configurando o máximo de informação, em bits por operação molecular que uma máquina molecular pode manipular. Como Schneider afirma ao traduzir o teorema de Shannon da canal capacidade para a biologia molecular:
“Ao aumentar o número de peças móveis, independentemente que podem interagir de forma cooperativa para tomar decisões, uma máquina molecular pode reduzir a freqüência de erros (taxa de escolhas incorretas) para qualquer arbitrariamente baixo nível é necessário para a sobrevivência do organismo, mesmo quando a máquina opera perto de sua capacidade e dissipa pequenas quantidades de energia.”(Schneider, 1991)
Nível 2. A Segunda Lei: Demônio de Maxwell, e os limites dos computadores:
A Segunda Lei da Termodinâmica pode ser expressa pela equação:

Seguindo Schneider, a equação afirma que, para uma dada quantidade de calor dQ entrando em um volume em alguma temperatura T, a entropia aumentará dS pelo menos por um fator dQ/T. A partir daí é possível relacionar a entropia à incerteza de Shannon caso as probabilidades que descrevem os estados do sistema sejam as mesmas para ambas as funções, como é o caso das máquinas moleculares. Schneider a partir desta conexão, e também por causa da temperatura constante em que as máquinas moleculares operam, reescreve a Segunda Lei da seguinte forma:
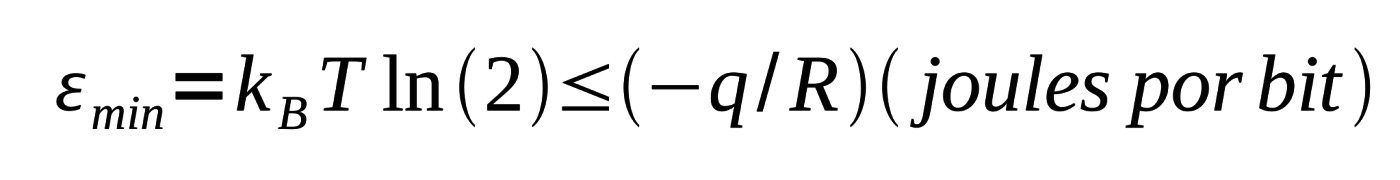
onde kB é a constante de Boltzmann. Isso indica que existe uma relação entre a informação R e o calor q. Notavelmente, esse mesmo limite pode ser determinado a partir da capacidade do canal (equação (5)) e a capacidade da máquina. A interpretação desta equação é simples: Existe uma quantidade mínima de energia térmica que deve ser dissipada (q negativo) por uma máquina molecular para que ela ganhe R = 1 bit de informação.
O Demônio de Maxwell é uma criatura mítica, originalmente criado como um experimento mental. Este ser supostamente seria capaz de abrir e fechar uma porta minúscula entre dois recipientes de gás. Então, ao observar as moléculas que se aproximam da porta e controlando a abertura de forma adequada, o demônio poderia permitir que as moléculas rápidas passem para um lado e as mais lentas para o outro. Schneider lembra que qualquer biólogo molecular esperaria que os músculos e os olhos do demônio usassem energia, o que é negligenciado pelos físicos. Outro fator digno de nota é que eles, os físicos, presumem que a energia utilizada para abrir a porta pode ser recuperada quando esta é fechada, se ela estiver ligada a uma mola.
A conclusão padrão é que um demônio, como este, poderia presumivelmente criar uma diferença temperatura macroscópica entre os dois recipientes, o que poderia ser usado para fazer funcionar um motor térmico. Aparentemente, o demônio poderia fornecer energia simplesmente através da escolha entre duas alternativas, o que violaria a Segunda Lei da Termodinâmica. Schneider, então, conclui:
A equação (7) se aplica a este problema. O demônio sempre seleciona as moléculas em cada cenário em que ele aparece. Somos enganados pela história, entretanto, porque o processo seletivo não é explicitamente declarado como invocando a segunda lei. Mas a Segunda Lei exige sempre a dissipação de energia térmica para compensar as seleções feitas. Assim, o demônio não é mais um enigma. A equação (7), aplica-se tanto às máquinas moleculares quanto aos computadores, por isso estabelece um limite para a computação. É impossível chegar a temperatura de zero absoluto porque isso implicaria em energia infinita para remover toda a energia térmica. Em qualquer temperatura acima do zero absoluto, um computador deve dissipar a energia para fazer escolhas. Como essa energia tem que vir de algum lugar, devemos alimentar o computador com energia para que o computador pode dissipá-la, enquanto o calcula nossas respostas. (Schneider, 1994)
Estes e outros insights têm sido possíveis ao encarar-se de forma sincera e direta as implicações da teoria da informação em sistemas biológicos, utilizando-se de conhecimentos apropriados da teoria de Shannon em si e dos próprios sistemas biológicos em questão, não através de caricaturas superficiais, como insistem os criacionistas das mais diversas estirpes.
Por causa deste tipo de atitude pretensiosa, entranhadas nos argumentos criacionistas, alguns cientistas propõe desafios de compreensão mínima dos conceitos relevantes (veja o teste proposto pelo matemático Jeffrey Shallit) aos criacionistas que não conseguem deixar de usar o linguajar da teoria da informação, tanto na sua variante computacional (a teoria algorítmica da informação de Kolmogorov e Chaintin) como na sua versão estatística, a de Shannon. Também recomendada é a análise de Shallit dos absurdos escritos por Stephen C. Meyers sobre a teoria da informação e evolução biológica em seu último livro (Veja aqui)
Os trabalhos de Schneider são um dos exemplos mais interessantes de como a aplicação do formalismo de Shannon por cientistas, que conheçam realmente os sistemas biológicos, pode trazer resultados elegantes e úteis e contribuir para o conhecimento científico básico e aplicado.
Os modelos de Schneider, entretanto, vão ainda mais além, pois mostram também como a seleção natural pode aumentar o conteúdo informacional de sistemas biomoleculares particulares (no caso as seqüencias de ligação no DNA para fatores de transcrição, por exemplo) quando quantificada por um métrica teoricamente sólida e não uma caricatura pseudo-matemática como as dos defensores do DI. Veja Schneider (2000) e os materiais sobre o programa Ev, disponíveis em seu site aqui e aqui, mas principalmente nesta Faq.
Em um próximo post, pretendo entrar mais nestas questões e apresentar outras propostas teóricas para a análise e quantificação da informação em sistemas biológicos, inclusive na evolução dos mesmos. Aí, nos depararemos com outro termo muito falado mas pouco compreendido, a "complexidade".
__________________________________________________________________________
Referências:
Fabris F. "Shannon Information Theory and Molecular Biology", Journal of Interdisciplinary Mathematics, vol.12, n.1, february 2009, pp. 41-87
Godfrey-Smith, P Information in Biology," in D. Hull and M. Ruse (eds.), The Cambridge Companion to the Philosophy of Biology. Cambridge University Press, 2007, pp. 103-119.
Griffiths, P.E (2001) Genetic Information: A metaphor in search of a theory. Philosophy of Science68(3): 394-412
Koonin EV. A non-adaptationist perspective on evolution of genomic complexity or the continued dethroning of man. Cell Cycle. 2004 Mar;3(3):280-5. Epub 2004 Mar 1. PubMed PMID: 14726650.
Lynch, Michael “The Origins of Genome Architecture”, 2007, Sinauer Associates, ISBN 9780878934843
Schneider TD. Claude Shannon: biologist. The founder of information theory used biology to formulate the channel capacity. IEEE Eng Med Biol Mag. 2006 Jan-Feb;25(1):30-3. PubMed PMID: 16485389; PubMed Central PMCID: PMC1538977.
Schneider TD, Stormo GD. Excess information at bacteriophage T7 genomic promoters detected by a random cloning technique. Nucleic Acids Res. 1989 Jan 25;17(2):659-74. PubMed PMID: 2915926; PubMed Central PMCID: PMC331610.
Schneider TD. Theory of molecular machines. I. Channel capacity of molecular machines. J Theor Biol. 1991 Jan 7;148(1):83-123. PubMed PMID: 2016886.
Schneider TD, Stephens RM. Sequence logos: a new way to display consensus sequences. Nucleic Acids Res. 1990 Oct 25;18(20):6097-100. PubMed PMID: 2172928; PubMed Central PMCID: PMC332411.
Schneider TD. Theory of molecular machines. II. Energy dissipation from molecular machines. J Theor Biol. 1991 Jan 7;148(1):125-37. PubMed PMID: 2016881.
Schneider, T. D. Sequence logos, machine/channel capacity, Maxwell's demon, and molecular computers: a review of the theory of molecular machines. Nanotechnology, 5:1{18, 1994. http://www-lmmb.ncifcrf.gov/ toms/paper/nano2/.
Schneider, T.D. Shannon’s Channel Capacity Theorem: is it about Biology? Apresentação [disponívle na URL: http://netresearch.ics.uci.edu/mc/nsfws08/slides/S3_schneider.pdf]
Schneider, T. D. New approaches in mathematical biology: Information theory and molecular machines. In Julian Chela-Flores and Francois Raulin, editors, Chemical Evolution: Physics of the Origin and Evolution of
Life, pages 313{321, Dordrecht,The Netherlands, 1996. Kluwer Academic Publishers.
Schneider TD. Evolution of biological information. Nucleic Acids Res. 2000 Jul 15;28(14):2794-9. PubMed PMID: 10908337; PubMed Central PMCID: PMC102656.
Schneider, Thomas D. Information Theory Primer With an Appendix on Logarithms (version = 2.64 of primer.tex 2010 Jan 08) [disponível URL: http://alum.mit.edu/www/toms/papers/primer/primer.pdf]
Shallit, Jeffrey (2010) Stephen Meyer's Bogus Information Theory Talkreason [disponível na URL: http://www.talkreason.org/articles/stephen-meyers.cfm] acessado em 20 de outubro de 2010.
Segal J. The use of information theory in biology: a historical perspective. Hist Philos Life Sci. 2003;25(2):275-81. PubMed PMID: 15295870.
Touretzky, David S. Basics of Information Theory (Tutorial Version of 24 November 2004), [disponível na URL:http://www.cs.cmu.edu/~dst/Tutorials/Info-Theory/]
http://commons.wikimedia.org/wiki/File:Janus-Vatican.JPG (autor: Fubar Obfusco)
PASIEKA / SCIENCE PHOTO LIBRARY
PHOTO (c) ESTATE OF FRANCIS BELLO / SCIENCE PHOTO LIBRARY
VICTOR DE SCHWANBERG / SCIENCE PHOTO LIBRARY
SCIENCE PHOTO LIBRARY
{kind=link}